GPT-2 no habla español: Artificial Intelligence, Anglocentrism, and the non-human side of DH
By Caroline B. Colquhoun and Sahai Couso Díaz, Mellon Graduate Student Fellows for the Digital Humanities 2020-2021, CMAP, Department of Spanish & Portuguese
“Have you ever wondered what it would be like if a computer wrote a blog post? I mean, let’s face it – if a computer could write a blog, then there would be no reason to bother with the task of writing blog posts. How would you know the posts would be good? The answer is, you wouldn’t, but perhaps you would not even know you were reading what was written by the computer at all…”
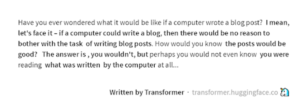
[Bolded text is GPT-2 generated, regular text is human prompts]
We asked a language model transformer called GPT-2 to wax meta-existential and write the introduction for a blog about AI-generated text based on a brief prompt we supplied, and we are fairly certain we might have fooled an unsuspecting reader or two (not unlike this journalistic prank the Guardian attempted to play on readers using the upgraded version of the same technology, “A robot wrote this entire article. Are you scared yet, human?”).
Then, being the good Hispanists and hispanohablantes (Spanish-speakers) that we are, we tried out a prompt in Spanish. The result was an almost unreadable, broken text. The garbled predictions lack grammatical and orthographic accuracy; even out of context, they simply are not comprehensible language. It is evident: GPT-2 no habla español.
“Pero si intentas escribir algo en español, quien tienen las escribiras. Habla por esa escrib ir o mejor para los nueve esc rib idos en el…. ¿Ves? No funciona muy bueno que no ? ¿”

But before we dive into a discussion of the programmed Anglocentrism at play–and our ambitious plans to try to address it–we will first provide a brief background and a basic explanation of the tool itself.
What on earth is GPT-2?
Once considered an AI “too dangerous to release,” OpenAI’s GPT-2 language model is a deep learning model programmed to generate the next “token” (word) in a given sequence of text. Trained on a very large text corpus (8 million web pages), its programmed objective is to predict the statistically most probable next word or phrase, given the preceding text.
In simple but technical words, text produced by GPT is considered “synthetic data” (see this post for other examples), or outputs that are algorithmically generated through unsupervised learning techniques and similar to the inputs or prompts provided to the AI.
Breaking down the acronym:
- Generative–the model can generate or predict in an unsupervised way
- Pretrained–OpenAI made a massive and powerful language model that they fine-tuned for the task of machine writing
- Transformer–This describes the kind of Natural Language Processing (NLP) “architecture” used to build GPT-2. For an explanation of this architecture (and the others that preceded it like GRU, RNN, or LSTM), see this post.
- 2–this was the second version, released in February 2019.
While human humanists like us were trying to wrap our organic brains around the implications, consequences, ethics, and potential applications of this new technology (full disclosure: we were fine-tuning a model to co-write a noir film screenplay based on a corpus of James M. Caine models), a new version was already in the works. And in June 2020, OpenAI published GPT-3. In less than 2 years we already have a new version on the market and, as many have highlighted, it is “shockingly good.” As Cade Metz pointed out in a recent New York Times article, GPT-3 is already capable of generating “tweets, pen[ning] poetry, summariz[ing] emails, answer[ing] trivia questions, translat[ing] languages and even writ[ing] its own computer programs.” In reference to the new version, some have even speculated that artificial intelligence is getting closer to passing the Turing Test (“GPT-3, explained”). Since GPT-3 is getting “smarter,” experts anticipate all kinds of future uses–including potentially dangerous applications by scammers, criminals, and morally bankrupt politicians, but also including some inspirational artistic and pedagogical applications. It is worth highlighting Ole Molvig’s Writing with Einstein project, as well as GPT-2 trained to write like Shakespeare or Rowling. Additionally, the OpenAI transformer has inspired a slew of creative projects, like GPT turned chef, GPT-2 acting as Nostradamus and as an oracle for 2020 (perhaps GPT-2’s biggest challenge yet). Beyond AI cooking up recipes and prophecies, we can even find GPT-2 generating text for an indie adventure game —a model for what Huan and Raley have called the “future human-AI collaborative creative practices”–and some believe that synthetic text will soon replace screenwriters.
While we acknowledge the significance of the broader ethical and ontological discussions around artificial intelligence (Bostrom and Yudowsky; Searle; Wallach and Allen), our focus for this blog–and the project that informs it–centers more on the biases that are programmed into these infrastructures. In their vital and urgent scholarly contributions, thinkers like Adam Hadhazy, Safiya Noble, Sara Wachter-Boettcher, and others call attention to another problematic facet of emerging AI technologies: they are programmed by (inherently biased) humans, which means, rather than representing an “impartial” mechanized or randomized position, algorithms reproduce the same prejudices of their programmers. GPT-2, for example, is fine-tuned on a corpus of texts that reflect the collective biases of their human authors, and those biases become embedded in the outputs and capabilities of the transformer–down to the very fundamental aspect of language choice. Anglocentrism is not an isolated issue to new technologies; as Roopika Risam, Thea Pitman and Claire Taylor, Simon Mahony and Jin Gao, and others note, the linguistic legacies of implicit biases (themselves rooted in the coloniality of knowledge) are also plainly visible in digital humanities.
“A final significant area of intervention for postcolonial digital humanities that speaks to the role of cultural critique in digital humanities is the centrality of the English language. Just as English has significant value for programming languages, it has also become the lingua franca within digital humanities. The role of English in digital humanities reflects the larger cultural dynamics of colonialism that have established English as a world language.” (Risam 44)
Hence, responding to the issue of the technological Anglocentrism we have observed in our own scholarly experimentation with AI fine-tuning, and motivated by the call to decolonize and linguistically de-center digital humanities and the technological tools it employs, our project intervenes at the intersection of DH and AI’s shared linguistic gap by interrogating the ethical dimensions of Anglocentric AI-generated synthetic texts and seeking belated solutions. Arguably, this issue is one that ought to be rectified at an earlier stage of the programming process; indeed, this is something that could be accomplished by heeding the calls of Noble and others to diversify both STEM education and hiring practices in Silicon Valley. Lacking the necessary resources to create our own transformer from scratch, however, our challenge is to work with the available, pre-trained (in English) GPT-2 model and fine-tune it to comprehensively “speak” (text-generate) in Spanish.
As we will describe in the next post in our series, our first attempts were none-too-successful, but we are hopeful that a breakthrough is on the horizon…
Stay tuned!
Part 2 Now Available!