Zenk, Maximilian, Baid, Ujjwal, Pati, Sarthak, Linardos, Akis, Edwards, Brandon, Sheller, Micah, Foley, Patrick, Aristizabal, Alejandro, Zimmerer, David, Gruzdev, Alexey, Martin, Jason, Shinohara, Russell T., Reinke, Annika, Isensee, Fabian, Parampottupadam, Santhosh, Parekh, Kaushal, Floca, Ralf, Kassem, Hasan, Baheti, Bhakti, Thakur, Siddhesh, Chung, Verena, Kushibar, Kaisar, Lekadir, Karim, Jiang, Meirui, Yin, Youtan, Yang, Hongzheng, Liu, Quande, Chen, Cheng, Dou, Qi, Heng, Pheng-Ann, Zhang, Xiaofan, Zhang, Shaoting, Khan, Muhammad Irfan, Azeem, Mohammad Ayyaz, Jafaritadi, Mojtaba, Alhoniemi, Esa, Kontio, Elina, Khan, Suleiman A., Mächler, Leon, Ezhov, Ivan, Kofler, Florian, Shit, Suprosanna, Paetzold, Johannes C., Loehr, Timo, Wiestler, Benedikt, Peiris, Himashi, Pawar, Kamlesh, Zhong, Shenjun, Chen, Zhaolin, Hayat, Munawar, Egan, Gary, Harandi, Mehrtash, Isik Polat, Ece, Polat, Gorkem, Kocyigit, Altan, Temizel, Alptekin, Tuladhar, Anup, Tyagi, Lakshay, Souza, Raissa, Forkert, Nils D., Mouches, Pauline, Wilms, Matthias, Shambhat, Vishruth, Maurya, Akansh, Danannavar, Shubham Subhas, Kalla, Rohit, Anand, Vikas Kumar, Krishnamurthi, Ganapathy, Nalawade, Sahil, Ganesh, Chandan, Wagner, Ben, Reddy, Divya, Das, Yudhajit, Yu, Fang F., Fei, Baowei, Madhuranthakam, Ananth J., Maldjian, Joseph, Singh, Gaurav, Ren, Jianxun, Zhang, Wei, An, Ning, Hu, Qingyu, Zhang, Youjia, Zhou, Ying, Siomos, Vasilis, Tarroni, Giacomo, Passerrat-Palmbach, Jonathan, Rawat, Ambrish, Zizzo, Giulio, Kadhe, Swanand Ravindra, Epperlein, Jonathan P., Braghin, Stefano, Wang, Yuan, Kanagavelu, Renuga, Wei, Qingsong, Yang, Yechao, Liu, Yong, Kotowski, Krzysztof, Adamski, Szymon, Machura, Bartosz, Malara, Wojciech, Zarudzki, Lukasz, Nalepa, Jakub, Shi, Yaying, Gao, Hongjian, Avestimehr, Salman, Yan, Yonghong, Akbar, Agus S., Kondrateva, Ekaterina, Yang, Hua, Li, Zhaopei, Wu, Hung-Yu, Roth, Johannes, Saueressig, Camillo, Milesi, Alexandre, Nguyen, Quoc D., Gruenhagen, Nathan J., Huang, Tsung-Ming, Ma, Jun, Singh, Har Shwinder H., Pan, Nai-Yu, Zhang, Dingwen, Zeineldin, Ramy A., Futrega, Michal, Yuan, Yading, Conte, Gian Marco, Feng, Xue, Pham, Quan D., Xia, Yong, Jiang, Zhifan, Luu, Huan Minh, Dobko, Mariia, Carré, Alexandre, Tuchinov, Bair, Mohy-ud-Din, Hassan, Alam, Saruar, Singh, Anup, Shah, Nameeta, Wang, Weichung, Sako, Chiharu, Bilello, Michel, Ghodasara, Satyam, Mohan, Suyash, Davatzikos, Christos, Calabrese, Evan, Rudie, Jeffrey, Villanueva-Meyer, Javier, Cha, Soonmee, Hess, Christopher, Mongan, John, Ingalhalikar, Madhura, Jadhav, Manali, Pandey, Umang, Saini, Jitender, Huang, Raymond Y., Chang, Ken, To, Minh-Son, Bhardwaj, Sargam, Chong, Chee, Agzarian, Marc, Kozubek, Michal, Lux, Filip, Michálek, Jan, Matula, Petr, Kerškovský, Miloš, Kopřivová, Tereza, Dostál, Marek, Vybíhal, Václav, Pinho, Marco C., Holcomb, James, Metz, Marie, Jain, Rajan, Lee, Matthew D., Lui, Yvonne W., Tiwari, Pallavi, Verma, Ruchika, Bareja, Rohan, Yadav, Ipsa, Chen, Jonathan, Kumar, Neeraj, Gusev, Yuriy, Bhuvaneshwar, Krithika, Sayah, Anousheh, Bencheqroun, Camelia, Belouali, Anas, Madhavan, Subha, Colen, Rivka R., Kotrotsou, Aikaterini, Vollmuth, Philipp, Brugnara, Gianluca, Preetha, Chandrakanth J., Sahm, Felix, Bendszus, Martin, Wick, Wolfgang, Mahajan, Abhishek, Balaña, Carmen, Capellades, Jaume, Puig, Josep, Choi, Yoon Seong, Lee, Seung-Koo, Chang, Jong Hee, Ahn, Sung Soo, Shaykh, Hassan F., Herrera-Trujillo, Alejandro, Trujillo, Maria, Escobar, William, Abello, Ana, Bernal, Jose, Gómez, Jhon, LaMontagne, Pamela, Marcus, Daniel S., Milchenko, Mikhail, Nazeri, Arash, Landman, Bennett, Ramadass, Karthik, Xu, Kaiwen, Chotai, Silky, Chambless, Lola B., Mistry, Akshitkumar, Thompson, Reid C., Srinivasan, Ashok, Bapuraj, J. Rajiv, Rao, Arvind, Wang, Nicholas, Yoshiaki, Ota, Moritani, Toshio, Turk, Sevcan, Lee, Joonsang, Prabhudesai, Snehal, Garrett, John, Larson, Matthew, Jeraj, Robert, Li, Hongwei, Weiss, Tobias, Weller, Michael, Bink, Andrea, Pouymayou, Bertrand, Sharma, Sonam, Tseng, Tzu-Chi, Adabi, Saba, Xavier Falcão, Alexandre, Martins, Samuel B., Teixeira, Bernardo C. A., Sprenger, Flávia, Menotti, David, Lucio, Diego R., Niclou, Simone P., Keunen, Olivier, Hau, Ann-Christin, Pelaez, Enrique, Franco-Maldonado, Heydy, Loayza, Francis, Quevedo, Sebastian, McKinley, Richard, Slotboom, Johannes, Radojewski, Piotr, Meier, Raphael, Wiest, Roland, Trenkler, Johannes, Pichler, Josef, Necker, Georg, Haunschmidt, Andreas, Meckel, Stephan, Guevara, Pamela, Torche, Esteban, Mendoza, Cristobal, Vera, Franco, Ríos, Elvis, López, Eduardo, Velastin, Sergio A., Choi, Joseph, Baek, Stephen, Kim, Yusung, Ismael, Heba, Allen, Bryan, Buatti, John M., Zampakis, Peter, Panagiotopoulos, Vasileios, Tsiganos, Panagiotis, Alexiou, Sotiris, Haliassos, Ilias, Zacharaki, Evangelia I., Moustakas, Konstantinos, Kalogeropoulou, Christina, Kardamakis, Dimitrios M., Luo, Bing, Poisson, Laila M., Wen, Ning, Vallières, Martin, Loutfi, Mahdi Ait Lhaj, Fortin, David, Lepage, Martin, Morón, Fanny, Mandel, Jacob, Shukla, Gaurav, Liem, Spencer, Alexandre, Gregory S., Lombardo, Joseph, Palmer, Joshua D., Flanders, Adam E., Dicker, Adam P., Ogbole, Godwin, Oyekunle, Dotun, Odafe-Oyibotha, Olubunmi, Osobu, Babatunde, Shu’aibu Hikima, Mustapha, Soneye, Mayowa, Dako, Farouk, Dorcas, Adeleye, Murcia, Derrick, Fu, Eric, Haas, Rourke, Thompson, John A., Ormond, David Ryan, Currie, Stuart, Fatania, Kavi, Frood, Russell, Simpson, Amber L., Peoples, Jacob J., Hu, Ricky, Cutler, Danielle, Moraes, Fabio Y., Tran, Anh, Hamghalam, Mohammad, Boss, Michael A., Gimpel, James, Kattil Veettil, Deepak, Schmidt, Kendall, Cimino, Lisa, Price, Cynthia, Bialecki, Brian, Marella, Sailaja, Apgar, Charles, Jakab, Andras, Weber, Marc-André, Colak, Errol, Kleesiek, Jens, Freymann, John B., Kirby, Justin S., Maier-Hein, Lena, Albrecht, Jake, Mattson, Peter, Karargyris, Alexandros, Shah, Prashant, Menze, Bjoern, Maier-Hein, Klaus, & Bakas, Spyridon. (2025). Towards fair decentralized benchmarking of healthcare AI algorithms with the Federated Tumor Segmentation (FeTS) challenge. *Nature Communications, 16*(1), 6274. https://doi.org/10.1038/s41467-025-60466-1
Competitions are commonly used to test and compare computer algorithms for analyzing medical images. However, these competitions usually rely on small, carefully chosen datasets collected from only a few hospitals. This doesn’t reflect the reality of working with patient data from many different medical centers, which can vary a lot. The Federated Tumor Segmentation (FeTS) Challenge was designed to better reflect real-world conditions. It tests two things: (i) how well federated learning methods (where data stays at each hospital and only the model updates are shared) can combine information from different locations, and (ii) how well the latest tumor segmentation algorithms perform across a wide range of data sources.
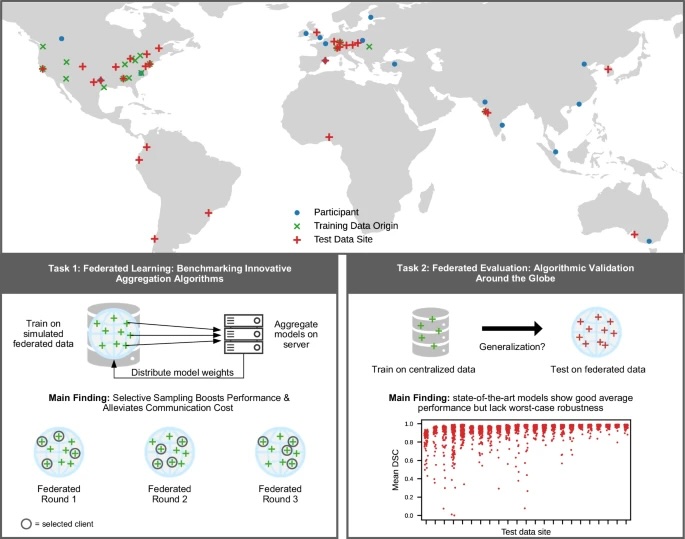
The challenge used brain tumor data from many hospitals to simulate how federated learning would work in real life. The results showed that algorithms that could adaptively combine information from different sites did better, and selecting which hospitals (clients) to involve at each step helped save time and resources. When the best segmentation algorithms were tested using brain scan data from 32 institutions around the world, they generally performed well, but in some cases, they struggled due to differences in the data. This shows that using data from many sites is important for making sure healthcare AI tools actually work in the real world.
Fig. 1: Concept and main findings of the Federated Tumor Segmentation (FeTS) Challenge.
The FeTS challenge is an international competition to benchmark brain tumor segmentation algorithms, involving data contributors, participants, and organizers across the globe. Test data hubs are geographically distributed while training data is centralized. Participants include those from the 2021 and 2022 challenges. Task 1 focused on simulated federated learning and we consistently saw an increase in performance by teams utilizing variants of selective sampling in their federated aggregation. In Task 2, submissions are distributed among the test data hubs for evaluation. As a representative example, the top-ranked model shows good average segmentation performance (measured by the Dice Similarity coefficient, DSC) but also failures for individual cases. Cases with empty tumor regions and data sites with less than 40 cases are not shown in the strip plot. Source data are provided as a Source Data file.