Zhu, Yanfan; Lyngaas, Issac; Meena, Murali Gopalakrishnan; Koran, Mary Ellen I.; Malin, Bradley; Moyer, Daniel; Bao, Shunxing; Kapadia, Anuj; Wang, Xiao; Landman, Bennett; Huo, Yuankai. “Scale-up Unlearnable Examples Learning with High-Performance Computing.” IS and T International Symposium on Electronic Imaging Science and Technology 37, no. 12 (2025): HPCI-184. https://doi.org/10.2352/EI.2025.37.12.HPCI-184.
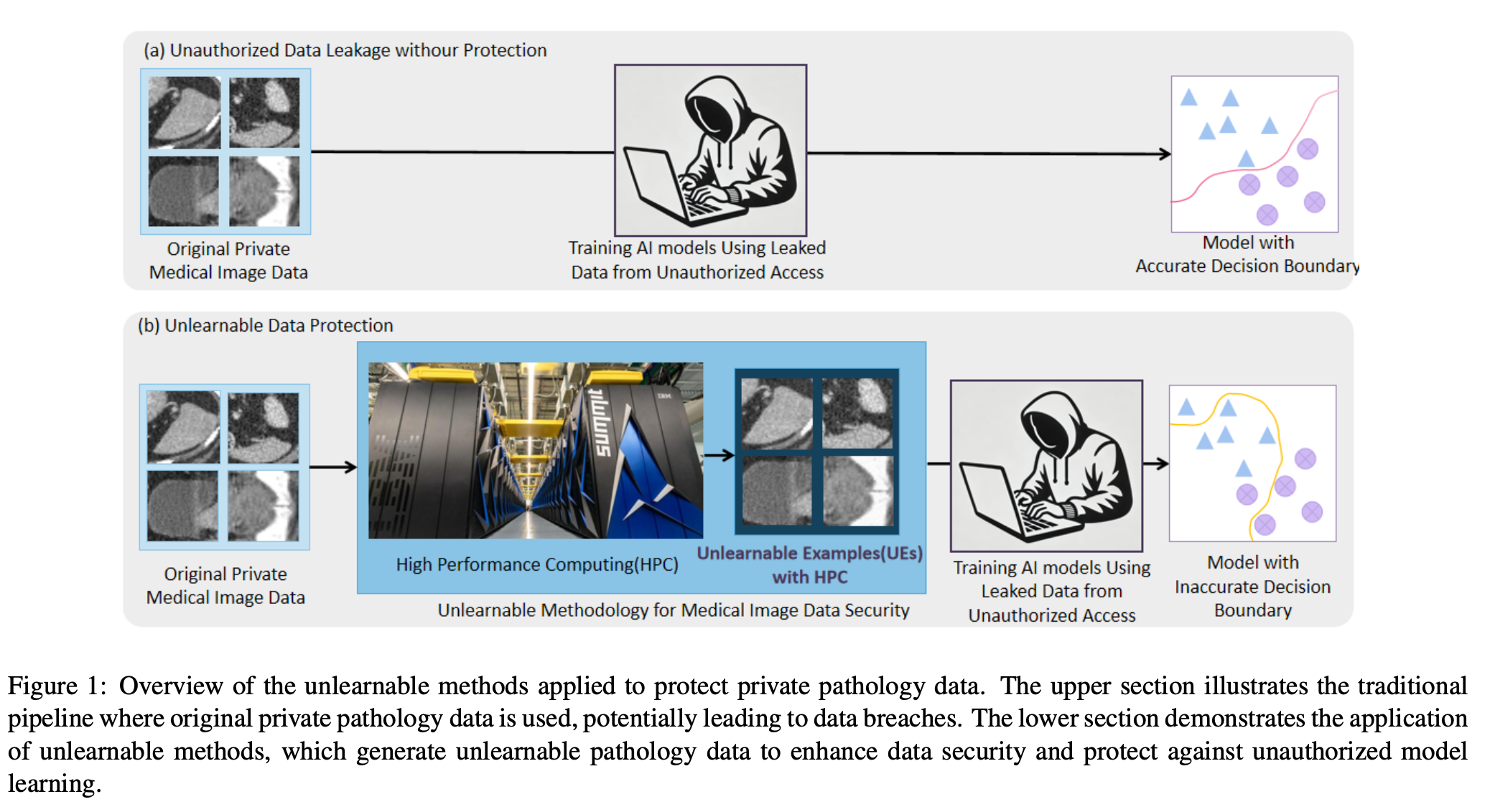
New AI tools like ChatGPT are designed to remember what users say to improve performance. But in healthcare, this can be risky—especially when radiologists use AI tools online to analyze medical images. There’s a real concern that these private images might be reused to train future AI systems without permission. This raises important questions about privacy and ownership of medical data.
To tackle this issue, researchers have come up with something called Unlearnable Examples (UEs). These are specially altered pieces of data that AI models can’t learn from, helping protect sensitive information. One of the most promising methods in this area is called Unlearnable Clustering (UC). It works better with larger groups of data (called batch sizes), but until now, it was limited by how much computing power was available.
To test what UC can really do when computing power isn’t an issue, the researchers used one of the world’s fastest supercomputers—Summit. They trained models using a method called Distributed Data Parallel (DDP), which allows many computers to work together at once. They tested this method on different image datasets like pictures of pets, flowers, and medical scans, to see how well it could make the data unlearnable.
They found that both very large and very small batch sizes could cause problems with performance. Interestingly, how well this method worked depended on the type of data, meaning there’s no one-size-fits-all solution. Choosing the right batch size for each dataset is key to making sure the data stays protected.
Thanks to the speed and power of Summit and the DDP method, they were able to run these experiments efficiently and consistently. The results show that with the right tools and strategies, it’s possible to protect sensitive data from being used by AI models without permission. The team has made their code freely available at: https://github.com/hrlblab/UE_HPC.