Wan, Zhiyu; Guo, Yuhang; Bao, Shunxing; Wang, Qian; Malin, Bradley A. “Evaluating Sex and Age Biases in Multimodal Large Language Models for Skin Disease Identification from Dermatoscopic Images.” Health Data Science 5 (2025): 256. https://doi.org/10.34133/hds.0256.
Multimodal large language models (LLMs), like ChatGPT-4, have shown promise in healthcare, especially in areas like identifying skin diseases. However, there are concerns about how reliable these models are and whether they have any biases. In this study, we tested two popular models, ChatGPT-4 and LLaVA-1.6, to see how well they could identify three types of skin conditions—melanoma, melanocytic nevi, and benign keratosis-like lesions—using a dataset with around 10,000 images. We wanted to check if the models performed differently based on a person’s sex or age.
When we compared the performance of ChatGPT-4 and LLaVA-1.6 with three other deep learning models, we found that ChatGPT-4 and LLaVA-1.6 did better overall than the traditional models, with ChatGPT-4 being 3% better and LLaVA-1.6 being 23% better. However, both models did worse than another advanced model called Swin-B. When it came to bias, ChatGPT-4 showed no bias toward any sex or age group, while LLaVA-1.6 was fair across all age groups but had some bias in sex. In contrast, Swin-B was found to be biased when identifying melanocytic nevi.
Overall, the study suggests that LLMs like ChatGPT-4 and LLaVA-1.6 can be useful and fair tools for helping doctors with diagnosing skin conditions and screening patients. However, to be sure about their reliability and fairness, future research needs to test these models on even larger and more varied datasets.
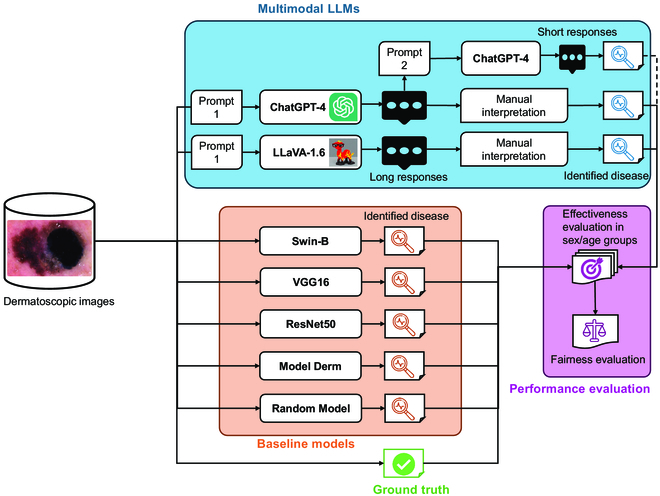
Fig. 1. A flowchart describing the fairness evaluation framework for multimodal large language models (LLMs) in skin disease identification. ChatGPT, Chat Generative Pre-trained Transformer; LLaVA, Large Language and Vision Assistant; VGG, Visual Geometry Group; ResNet, Residual Network.